【转载】开源软件架构之SQLAlchemy翻译
【本文转载自:开源软件架构之SQLAlchemy翻译】,原文如下:
本文翻译自*The Architecture of Open Source Applications*第二卷第20章。
原文:SQLAlchemy at Architecture of Open Source Applications
翻译者:nettee
SQLAlchemy诞生于2005年,是一个Python语言的数据库工具包和对象关系映射(ORM)系统。在一开始,SQLAlchemy是一个提供使用Python数据库API(DBAPI)处理关系数据库的端到端系统。它的核心特性包括顺畅地处理复杂的SQL查询和对象映射和“工作单元”(unit of work)模式的实现。这些特性使得SQLAlchemy能够提供高度自动化的数据库系统,因此SQLAlchemy在很早期的几个版本里就受到了大量的关注。
SQLAlchemy从一个小的、实现粗糙的概念开始,通过一系列的修订迅速进步。在用户技术不断增长的同时,内部架构和外部API也在迭代更新。在2009年1月0.5版本面世时,SQLAlchemy已经在大范围的生产部署后稳定了下来,到了0.6版本(2010年4月)和0.7版本(2011年5月),架构和API的改进使得生产最高效和最稳定的库成为可能。在写作本文时,SQLAlchemy已经在多个领域中被大量组织所采用。在很多人眼中,它已经成为Python关系数据库处理事实上的标准。
数据库抽象面临的挑战
术语“数据库抽象”通常用来表示一个隐藏了数据存储和查询的细节的系统。人们有时候会把这个术语极端化,认为不仅关系数据库的细节应当被系统隐藏,甚至连关系结构本身都应当隐藏,用户不需要关心底层的存储结构是否是关系型的。
对ORM最常见的评论文章认为这种系统的主要目标就是如上所述——把关系数据库“藏起来”,接管构建数据库和与数据库交互的任务,降格为底层实现细节。这种方式的核心在于剥夺开发人员对关系结构进行设计和查询的能力,转交由不透明的库来处理。
经常和关系数据库打交道的人都知道,这种方式是完全不切实际的。关系结构和SQL查询的功能性很强,组成了软件设计的核心。如何设计、组织、操纵这些结构不仅取决于要查询哪些数据,还取决于数据的结构。如果隐藏了数据的结构,在一开始使用关系型数据库就没有意义了。
既要寻求屏蔽关系数据库底层细节的方法,又面对着关系数据库需要详尽的说明的事实。这种矛盾通常被称为“对象-关系阻抗失配”(object-relational impedance mismatch)问题。SQLAlchemy采用了一种比较新颖的方法来解决这个问题。
SQLAlchemy 解决数据库抽象的方法
SQLAlchemy认为开发人员必须考虑数据的关系结构。一个预先定义并隐藏数据模式(schema)和查询方法的系统只是在忽视关系型数据库的意义,导致传统的阻抗失配问题。
但与此同时,这些决定的实现可以在,也应该在尽可能高的层次模式上执行。建立对象模型和数据库模式间的关联、并在SQL查询中保持这种关联是一个重复性很高的工作。使用工具自动化执行这些任务,可以使应用开发更加简洁、高效。创建自动化工具的时间,远远少于手工实现这些操作的时间。
SQLAlchemy称自己是一个工具包,强调开发人员的角色应是关系结构及其与应用程序间联系的设计者和构建者,而不是被动地接受一个第三方库所做的决定。SQLAlchemy采取“不完全抽象”理念,暴露关系概念,鼓励开发者在应用程序和关系数据库之间裁剪出一个自定义的、但又是完全自动化的交互层。SQLAlchemy的创新之处在于,它在不牺牲开发者对于关系数据库的控制的同时,实现了高度的自动化。
核心层与ORM层
SQLAlchemy工具包的中心目标是在数据库交互的每一层都开放丰富的API,将任务划分为核心层和ORM层。核心层包括Python数据库API(DBAPI)的交互,生成数据库能够识别的SQL语句,以及模式(schema)管理。这些功能都通过公开的API来展现。ORM层,或者叫对象-关系映射层,则是构建在核心层上的一个特定的库。SQLAlchemy提供的ORM层只是可以构建在核心层上的众多对象抽象层的其中一个,很多开发者和组织是直接在核心层上构建自己的应用。
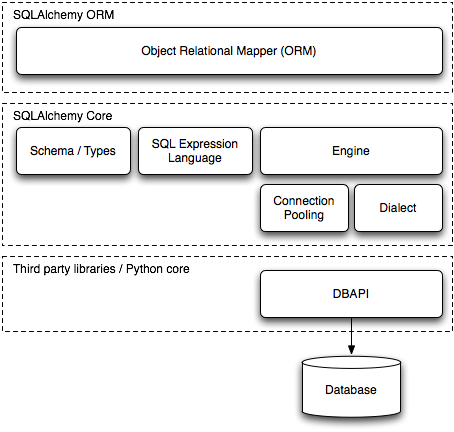
图20.1: SQLAlchemy层次图
核心层和ORM层的分离一直是SQLAlchemy最典型的特征,这个特征既有优点也有缺点。核心层的显式存在导致:(一)ORM需要将映射到数据库的类属性关联到一个叫Table的结构上,而不是直接关联到数据库中表述的字符串属性名。(二)ORM需要使用一个叫select的结构来产生SELECT查询,而不是直接将对象属性拼接成一个字符串的语句。(三)ORM需要从ResultProxy接受结果行(ResultProxy自动将select映射到每个结果行),而不是直接操纵数据库游标(cursor)将数据转化成用户定义的对象。
在一个很简单的以ORM为中心的应用中,核心层的元素可能是不可见的。然而,由于核心层是仔细地集成到ORM层,能够支持两个层次间流畅的转化的,一个复杂得多的ORM中心的应用,在形势所迫时,可以“下潜”一两个抽象层次,更具体、更细致地处理数据库。随着SQLAlchemy日渐成熟,ORM层提供了越来越多的全面周到的模式,核心层的API在常规使用中已经很少明显出现了。然而,核心层可操控也是SQLAlchemy早期成功的因素之一,因为这让早期的用户在ORM还不成熟的时候,可以做到很多看似不可能的事情。
核心层/ORM层的缺点是,一个指令必须经过更多的步骤。对于Python传统的C实现,单独的函数调用是额外开销的主要来源,导致了运行时速度缓慢。对此,传统的改善方法是通过重排和内联缩短调用链,并且将性能需求高的模块用C代码代替。SQLAlchemy多年来一直在用这两种方法来提升性能。然而,随着Python的PyPy解释器逐渐被接受,由于PyPy通过JIT的内联和编译减少了长调用链的影响,SQLAlchemy遗留的性能问题或许已经可以忽略,不需要使用C代码来代替。
改良DBAPI
SQLAlchemy的底层是一个通过DBAPI和数据库进行交互的系统。DBAPI本身不是一个实际的库,只是一个规范。因此,DBAPI有不同的实现,有的是针对特定的目标数据库,比如MySQL或PostgreSQL,有的是针对特定的非DBAPI数据库适配器,如ODBC和JDBC。
DBAPI为SQLAlchemy提出了两点挑战。一点挑战是为DBAPI的基本使用模式提供一个易用且功能全面的界面(译注:facade,即对外提供简化过的接口),另一点挑战是应对极其多变的DBAPI具体实现和数据库引擎。
方言系统
DBAPI描述的接口及其简单。它的核心组件就是DBAPI自己,连接(connection)对象,和游标(cursor)对象——“游标”在数据库中指一个语句(statement)和它相关的结果的上下文。它们相互配合,连接数据库并提取数据的一个简单的例子如下:
connection = dbapi.connect(user="user", pw="pw", host="host")
cursor = connection.cursor()
cursor.execute("select * from user_table where name=?", ("jack",))
print "Columns in result:", [desc[0] for desc in cursor.description]
for row in cursor.fetchall():
print "Row:", row
cursor.close()
connection.close()
SQLAlchemy在传统的DBAPI会话之上进行了封装。一开始调用create_engine,将连接和配置信息装配好,并返回一个Engine类的对象,通过这个对象访问不直接对外开放的DBAPI。
对于简单的语句执行,Engine提供了一个叫“隐式执行”(implicit execution)的接口。获取和关闭DBAPI连接的工作过程都被隐藏了起来:
engine = create_engine("postgresql://user:pw@host/dbname")
result = engine.execute("select * from table")
print result.fetchall()
从0.2版起,SQLAlchemy加入了Connection对象,提供显式维护DBAPI连接的功能:
conn = engine.connect()
result = conn.execute("select * from table")
print result.fetchall()
conn.close()
Engine、Connection两个类的execute方法返回的结果是一个ResultProxy,它提供了一个与DBAPI的游标类似但功能更丰富的接口。Engine,Connection和ResultProxy分别对应于DBAPI模块、一个具体的DBAPI连接对象,和一个具体的DBAPI游标对象。
在底层,Engine引用了一个叫Dialect的对象。Dialect是一个有众多实现的抽象类,它的每一个实现都对应于一个具体的DBAPI和数据库。一个为Engine而创建的Connection会咨询Dialect作出选择,对于不同的目标DBAPI和数据库,Connection的行为都不一样。
Connection创建时会从一个连接池获取并维护一个DBAPI的连接,这个连接池叫Pool,也和Engine相关联。Pool负责创建新的DBAPI连接,通常在内存中维护DBAPI连接池,供频繁的重复使用。
在一个语句执行的过程中,Connection会创建一个额外的ExecutionContext对象。这个对象从开始执行的时刻,一直存在到ResultProxy消亡为止。
图20.2说明了所有这些对象之间的关系,以及它们与DBAPI组件间的关系。
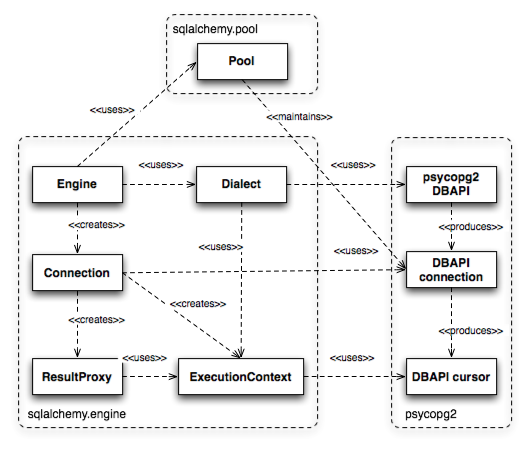
图20.2: Engine, Connection, ResultProxy API
处理DBAPI多变性
为了管理DBAPI多变的行为,首先我们需要考虑问题的领域。DBAPI的规约(目前是第二版)定义为一组很大程度上允许行为多变且留有许多未定义领域的API。于是,实际使用的DBAPI在多个领域都显示出很大程度的多变性,包括是否接受Python Unicode字符串,是否能够在INSERT语句执行后获取自动生成的主键,是否能说明参数的取值范围。这些DBAPI同样还有很多面对不同类型时的特殊行为,包括处理二进制、高精度数值、日期、布尔、Unicode等类型。
SQLAlchemy通过允许Dialect和ExecutionContext的多级子类多样性来解决这个问题。图20.3展示了当使用psycopg2时Dialect和ExecutionContext间的关系。PGDialect类提供了特定于PostgreSQL数据库的行为,包括ARRAY数据类型和schema catalog;PGDialect_psycopg2类提供了特定于psycopg2 DBAPI的行为,包括Unicode处理和服务器端游标行为。
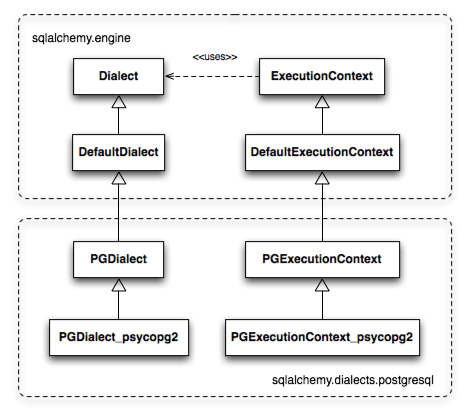
图20.3: 简单的Dialect/ExecutionContext继承体系
在处理支持多个数据库的DBAPI时,会出现上述模式的一个变体。这样的例子包括pyodbc(处理经由ODBC的任意数据库后端)和zxjdbc(一个处理JDBC的Jython驱动)。上述关系通过使用一个混入类(mixin class)得到扩展。混入类来自sqlalchemy.connectors包,提供了不同后端共有的DBAPI行为。图20.4展示了sqlalchemy.connectors.pyodbc中由不同的pyodbc方言(如MySQL方言和Microsoft SQL Server方言)共有的功能。
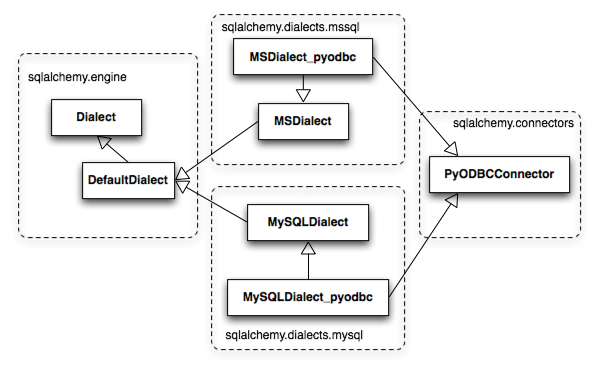
图20.4:dialect继承体系中的DBAPI行为
Dialect和ExecutionContext对象提供了定义与数据库和DBAPI的每一项交互的方法,包括连接的参数应该如何格式化,包括如何处理语句执行时的古怪行为。Dialect还生成了SQL编译构件(用于为目标数据库正确生成SQL)和类型对象(用于定义Python数据与目标DBAPI和数据库间如何互相转化)。
模式定义
在数据库连接和交互建立好之后,下一步就是要提供创建和操纵SQL语句的方法了。为了实现这一点,首先需要定义我们将如何表示数据库中的表和字段(column)——也即所谓的的“模式”(schema)。表和字段表示了数据的组织方式,大部分的SQL语句是由和它们相关的的表达式和命令组成的。
一个ORM或是数据访问层需要在程序级提供对SQL语言的访问,此方法的基础是描述表和字段的编程系统。SQLAlchemy在这里通过提供Table和Column构件,独立于用户的模型类定义描述数据库结构,将核心层和ORM层分离。将模式定义与ORM分离的原理在于,关系模式可以用关系数据库的术语(如果必要,还包括平台特定的细节)无歧义地设计,而无需对象-关系概念——这完全是两码事。独立于ORM组件也意味着模式描述系统对任何其他可能构建在核心层上的对象-关系系统都很重要。
Table和Column模型包含在一个叫做*metadata*(元数据)的概念内,用一个叫MetaData的集合对象代表Table对象的集合。这个结构主要源于Martin Fowler在*Patterns of Enterprise Application Architecture*一书中描述的“元数据映射”(MetaData Mapping)。图20.5展示了sqlalchemy.schema包中的一些关键元素。
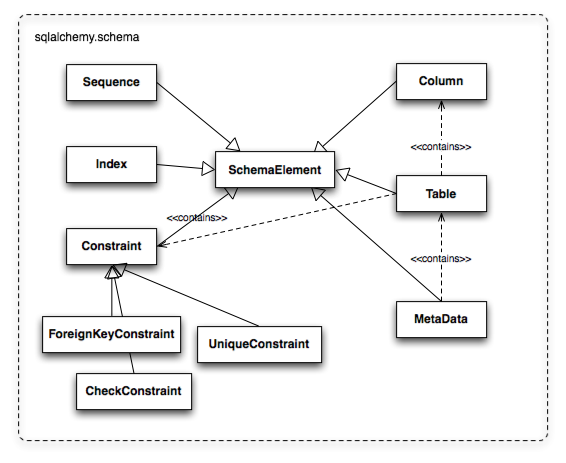
图20.5: sqlalchemy.schema基本对象
Table表示了目标schema中一个实际的表的名字等属性,它所含的Column对象集合代表了每个表中字段的名字和类型信息。Table中还含有一系列完整的描述constraint, index, sequence的对象,其中一些对引擎和SQL构建系统的行为影响很大。特别的,ForeignKeyConstraint在决定两个表如何进行连接上非常关键。
Table和Column相比schema包中的的其他类的独特之处在于他们是双重继承的,从sqlalchemy.schema和sqlalchemy.sql.expression包中同时继承。它们不仅是作为schema级的模块,也是SQL表达式语言的语法单元。这个关系在图20.6中展示。
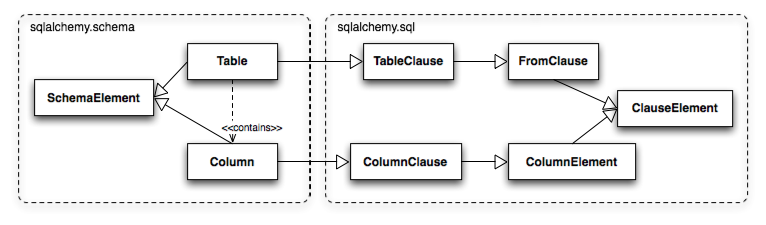
图20.6: Table和Column的双重身份
从图20.6中我们可以看出,Table继承自SQL的FromClause,即“你能select的对象”;Column继承自SQL的ColumnElement,即“你能在SQL表达式中使用的东西”。
SQL表达式
在SQLAlchemy诞生之初,如何生成SQL并不明确。一个文本语言是最可能的选择,因为这是一个普遍的方法,Hibernate’s HQL等知名的对象-关系工具都以此作为核心。然而,在Python中有一个更好的方法:使用Python的对象和表达式生成表达式树结构,甚至是重载Python的操作符使其表现出SQL语句的行为。
SQLAlchemy的表达式语言使用的Python对象和操作符主要受到lan Bicking的SQLObject中包含的SQLBuilder库的启发,虽然它也许不是第一个这么做的工具。在这种方式中,Python对象代表了一个SQL表达式的词法单元。这些对象的方法和重载的操作符就生成了源于它们的词法结构。最常见的对象是”Column”对象——SQLObject用一个映射到ORM上的类代表”Column”,放置在可以通过.q属性访问的命名空间里;SQLAlchemy则将属性命名为.c。这个.c属性一直保留到现在,在核心层的selectable元素,如表示table和select语句的元素上使用。
表达式树
SQLAlchemy中的SQL表达式很像在分析SQL语句中产生的结构——一个分析树。唯一的不同在于开发者是直接构造出一个分析树,而不是从一个字符串中分析得到。分析树上节点的核心类型叫做ClauseElement,图20.7描述了ClauseElement和其他一些关键的类之间的关系。
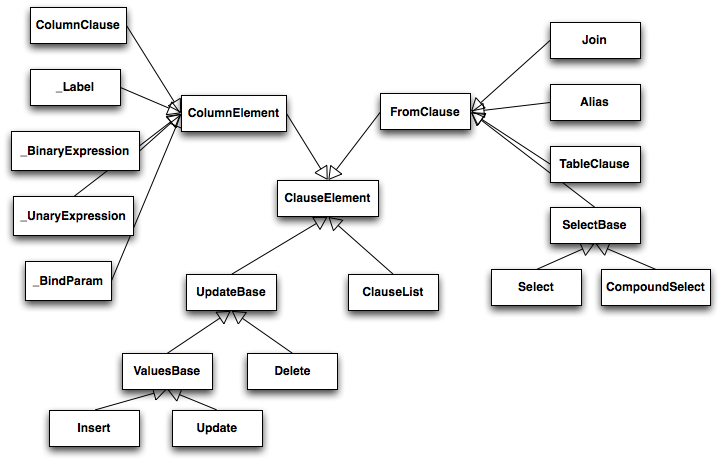
图20.7: 基本的表达式继承体系
通过使用构造函数,方法,重载的表达式,语句:
SELECT id FROM user WHERE name = ?
的结构可以这样在Python中构造出来:
from sqlalchemy.sql import table, column, select
user = table('user', column('id'), column('name'))
stmt = select([user.c.id]).where(user.c.name=='ed')
上面代码中select的结构如图20.8所示。注意到_BindParam中包含一个'ed'值,这会使SQL语句中产生一个用问号表示的bound parameter marker.
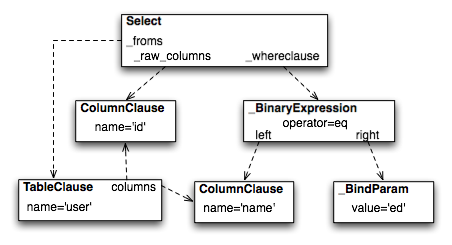
图20.8:表达式树示例
从树的图形上我们可以看出,一个简单的自顶向下遍历就可以快速产生出一条SQL语句。我们在后面语句编译的部分还会详细探究。
Python操作符
在SQLAlchemy中,一个像这样的表达式:
column('a') == 2
得到的既不是True也不是False,而是一个SQL表达式结构。做到这一点的核心在于使用Python特殊操作符函数(如__eq__, __ne__, __le__, __lt__, __add__, __mul__)实现的操作符重载。面向字段的表达式节点通过使用混入类ColumnOperators提供重载的操作符。使用操作符重载后,表达式column('a') == 2等价于:
from sqlalchemy.sql.expression import _BinaryExpression
from sqlalchemy.sql import column, bindparam
from sqlalchemy.operators import eq
_BinaryExpression(
left=column('a'),
right=bindparam('a', value=2, unique=True),
operator=eq
)
eq实际上是一个源于Python内置的operator的一个函数。将操作符表示为一个对象(如operator.eq)而不是一个字符串(如=)使字符串表示可以在语句编译时,针对具体的数据库方言指定。
编译
与SQL表达式树产生出字符串的SQL相关的中心类是Compiled类。这个类有SQLCompiler和DDLCompiler两个主要的子类。SQLCompiler为SELECT,INSERT,UPDATE,DELETE语句处理SQL渲染工作,这些语句统称为DQL(数据查询语言)和DML(数据操纵语言)。而DDLCompiler是处理CREATE和DROP语句的,这些语句统称为DDL(数据定义语言)。从TypeCompiler开始还有另一支类继承体系,关注类型的字符串表示。每个数据库方言提供自己的子类,继承自三个compiler type,来定义SQL语言特定于目标数据库的方面。图20.9提供了这个类继承体系关于PostgreSQL方言的概览。
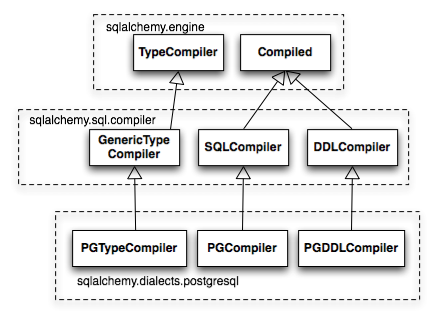
图20.9: 编译器继承体系,包括特定于PostgreSQL的实现
Compiled的子类提供了一系列的*visit*方法,每一个*visit*方法都被ClauseElement的一个特殊子类所引用。通过对(语法树上的)ClauseElement节点进行遍历,递归地连接每个visit函数的字符串输出,就构建出了一个语句。在这个过程中,Compiled对象维护关于匿名标识符名、bound parameter名,以及嵌套子查询的状态。这些都是为了产生出一个字符串形式的SQL语句,和带有默认值的bound parameter集合。图20.10展示了visit函数产生出字符串单元的过程。
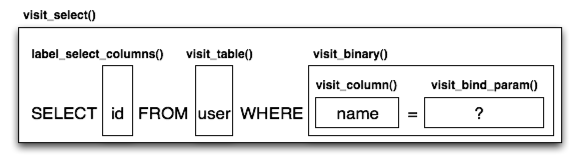
图20.10: 一个语句编译过程中的调用树
一个完整的Compiled结构包括完整的SQL字符串和绑定值的集合。ExecutionContext将他们强制转换为DBAPI的execute方法所期望的格式,包括如下方面的考虑:Unicode语句对象的处理,存储绑定值使用的集合类型,以及绑定值自己如何强制转换为适合DBAPI和目标数据库的表示的规范。
ORM的类映射
我们现在将注意力转移到ORM上来。第一个目标是使用我们定义的表元信息(table metadata)系统,允许从用户定义的类到数据库表中的字段集合的映射。第二个目标是基于数据库中表间的关系,允许定义用户定义的类之间的关系。
SQLAlchemy将这个叫做“映射”(mapping),这个名字来自Fowler的*Patterns of Enterprise Architecture*一书描述的著名的数据映射器模式(Data Mapper Pattern)。总体来看,SQLAlchemy的ORM很大程度上从Fowler详细描述的实践中借鉴而来。它还受到了著名的Java关系映射器Hibernate和lan Bicking的SQLObject的很大影响。
Classical vs. Declarative
我们使用术语*传统映射(classical mapping)*来指代SQLAlchemy将对象-关系数据映射应用到已存在的用户类的系统。这种映射形式取Table对象和用户定义的类,将两个独立定义的实体用一个叫mapper的函数结合在一起。一定mapper应用在一个用户定义的类上,这个类就新获得了与表中字段对应的属性:
class User(object):
pass
mapper(User, user_table)
# now User has an ".id" attribute
User.id
mapper还能给类加上其他的属性,包括对应于其他对象引用的属性,也包括对应于任意SQL表达式引用的属性。给一个类添加任意属性的过程在Python中叫做“猴子补丁”(monkeypatching)。然而,由于我们并不是任意地添加属性,而是用数据驱动的方式添加,这个行为用术语*class instrumentation*来表达更为准确。
SQLAlchemy近来的用法主要关注声明式(Declarative)扩展。声明式扩展是一个配置系统,看起来像是许多其他对象-关系工具使用的常见的类似活动记录的类声明系统。在这个系统中,最终用户显式在类定义中定义属性,每个属性代表类上一个需要被映射的属性。在大多数情况下,Table类和mapper函数都不会显式提及,只有类、Column对象、其他ORM相关的属性出现:
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
在上面的例子中,看起来是通过id = Column()直接实现了class instrumentation,但实际上并不是这样。声明式扩展使用一个Python元类(一种在一个类新定义时执行一系列操作的简便方法)来从已定义的类生成一个新的Table对象,并将这个对象和原来的类一起传给mapper函数,mapper函数用完全相同的方式实现功能,将它自己的属性附加到类上(在这个例子中,是id属性),取代原先的属性值。在元类的初始化完成时(即执行流离开User类描述的区块时),被id标记的Column对象已经移动到了一个新的Table中,并且User.id已经被一个特定于映射的新属性所取代。
SQLAlchemy看似应该有一个描述简单的声明式配置形式。然而,为了支持传统映射继续稳固化的工作,对声明式的支持被推迟了。在早期有一个叫ActiveMapper的临时扩展(后来成为了Elixir项目)支持声明式映射。它在一个高层的声明系统中重新定义了映射构件。声明式映射的目标是反转Elixir重度抽象方法的方向。它建立了一个系统,几乎原样保留了SQLAlchemy的传统映射概念,只是重新组织了它们的使用方式,使之更加简洁,并相比传统映射更适应类级扩展。
无论使用传统映射还是声明式映射,映射到的类都表现出新的特性,能够根据自己的属性表达SQL构件。SQLAlchemy原先继承了SQLObject的行为,使用一个特殊的属性来获取SQL字段表达式,在SQLAlchemy中这个属性叫做.c,如下面的例子:
result = session.query(User).filter(User.c.username == 'ed').all()
然而,在版本0.4中,SQLAlchemy将这个功能移到映射到的属性自身:
result = session.query(User).filter(User.username == 'ed').all()
这个属性访问上的变化被证明是一个巨大的进步,因为它允许在类上出现类似字段(而不是字段)的对象获得额外的特定于类的能力,这些能力并不直接源于底层的Table对象。它还允许不同类型的类属性的集成使用,比如指向直接表中字段的属性,指向从字段生出的SQL表达式的属性,还有指向相关类的属性。最终,它实现了映射类和映射类的实例的对称性,因为同样的属性在不同的类中会有不同的行为。类上的属性返回SQL表达式,而实例上的属性返回实际的数据。
映射剖析
添加到User类中的id属性是Python中的*描述符*(descriptor)对象——一个有__get__, __set__和__del__方法的对象,Python在运行时对所有关于这个属性的类的实例的操作都咨询它。SQLAlchemy的实现是InstrumentedAttribute,我们将用另一个例子揭示在此表象之下的内容。我们从一个Table和用户定义的类开始,建立了一个只有一个字段的映射,和一个定义了到相关类的引用的relationship:
user_table = Table("user", metadata,
Column('id', Integer, primary_key=True),
)
class User(object):
pass
mapper(User, user_table, properties={
'related':relationship(Address)
})
当映射是完整的时候,和这个类相关的对象的结构在图20.11中详细描述。
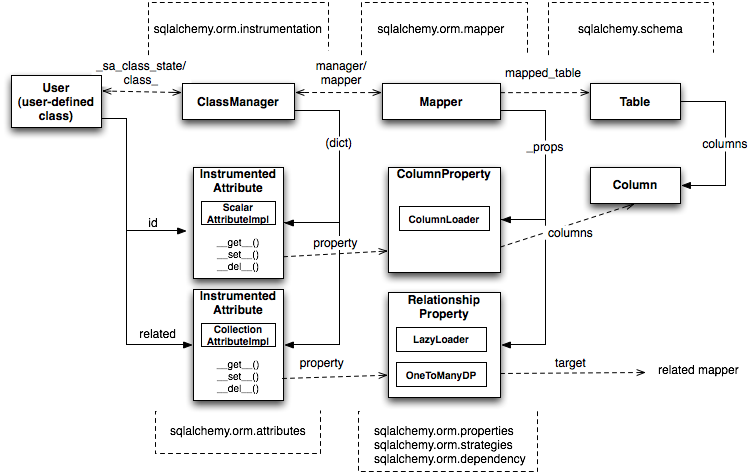
图20.11:映射剖析
这张图展示了SQLAlchemy的一个定义为两层分离的交互的映射,两层分别为用户定义的类和这个类映射到的表元数据。左半张图为class instrumentation,右半张图为SQL和数据库的功能。总体的模式为使用对象的组合来分离行为角色,使用对象继承区分一个角色下的行为差异。
在class instrumentation这半边,ClassManager和映射到的类相联系,而一组InstrumentedAttribute对象和映射到类上的每个属性相联系。InstrumentedAttribute还是前面提到的Python描述符,在基于类的表达式(如User.id==5中使用时,产生SQL表达式)。当处理User的一个实例时,InstrumentedAttribute将属性的行为委托给一个AttributeImpl对象——为所表示的数据定制的多个变体之一。
在映射这半边,Mapper代表了用户定义的类和一个可select单元(通常是Table)的关联。Mapper维护了一组MapperProperty属性对象,每个属性对象处理一个特定属性的SQL表示。MapperProperty最常见的变体是ColumnProperty(表示了一个映射到的字段或SQL表达式)和RelationshipProperty(表示了到另一个映射器的关联)。
MapperProperty将属性加载行为——包括属性如何在SQL语句中渲染,如何从结果行生成——委派给LoadStrategy对象。这个对象有多个变体,每个变体决定一个属性的加载行为是*推迟*(deferred),*急切*(eager),还是*立即*(immediate)。映射器配置时会选定一个默认的行为,在查询时可以选择使用其他的策略。RelationshipProperty还引用了一个DependencyProcessor,这个类决定映射器间的依赖和属性同步在刷新(flush,具体含义见下一节——译者注)时如何处理。DependencyProcessor的决定基于和关系尾部(parent)和头部(target)可SELECT部件的关系图形。
Mapper/RelationshipProperty结构组成了一个图,其中Mapper对象是结点,RelationshipProperty对象是有向边。一旦应用程序定义全了所有的映射器,一个叫做配置(configuration)推迟的“初始化”步骤就开始进行了。初始化功能主要是每个RelationshipProperty使用,确定它的尾部(parent)和头部(target)映射器间的细节,包括选择AttributeImpl和DependencyProcessor。这个图是贯穿整个ORM操作的关键,和很多过程相关:所谓的“连锁反应”(cascade),定义了操作如何沿着对象路径传播;查询操作中,相关对象和集合都“急切地”一次性加载;以及对象刷新部分,在开始一系列的持久化步骤前,建立所有对象的依赖图。
查询和加载行为
SQLAlchemy通过Query对象创建所有的对象加载行为。Query起始的基本状态包括*实体*(entity),它是被映射的类和(或)用于查询的SQL表达式的列表。它还有一个Session的引用,代表了到一个或多个数据库的连接,以及关于这些连接上的事务累积下来的缓存数据。下面是一个简单的例子:
from sqlalchemy.orm import Session
session = Session(engine)
query = session.query(User)
我们创建一个会产出User对象的Query,并和刚创建的Session关联起来。Query提供了一个生成式的构建模式(generative builder pattern)——前面讨论到的select构件也是这样的方式,一次方法调用会将额外的条件和修饰符关联到一个语句构件上。当在Query上调用一个迭代的操作时,它构建了一个SQL表达式结构表示一个SELECT,送往数据库,然后将结果集翻译为面向ORM的结果,对应于被查询实体的初始集合。
Query在SQL渲染(SQL rendering)和数据加载(data loading)的这两部分操作之间做了一个艰难的区分。前者指的是构造一个SELECT语句,而后者指的是将SQL结果行翻译为映射到ORM的结构上。实际上,没有SQL渲染这一步,也可以进行数据加载,因为Query可能会要从用户手写的文本查询翻译到结果。
一系列主要的Mapper对象可以看成是一个图,每个字段或拥有ColumnProperty的SQL表达式看做叶节点,而每个RelationshipProperty看做是指向另一个Mapper结点的边。SQL渲染和数据加载都利用了图上的递归下降遍历方法。在每个结点上执行的动作最终是和每个MapperProperty相关的LoaderStrategy的工作,它在SQL渲染阶段将字段和连接(join)添加到创建中的SELECT语句中,在数据加载阶段生成处理结果行的Python函数。
在数据加载阶段生成的Python函数接收一个从数据库中获取的行,结果是改变内存中一个映射属性的状态。这些函数是在检查结果集中第一个到来的行,为一个特定的属性生成的。它们还受加载选项的影响。如果属性不需要加载,就不会生成函数。
图20.12展示了在连接急切加载(joined eager loading)场景中,几个LoaderStrategy对象的遍历过程,说明了它们在Query的_compile_context方法中连接到一个渲染过的SQL语句。图中还展示了在Query的instansces方法中生成行填充(row population)函数的过程,接收结果行,并填充一个对象的属性。
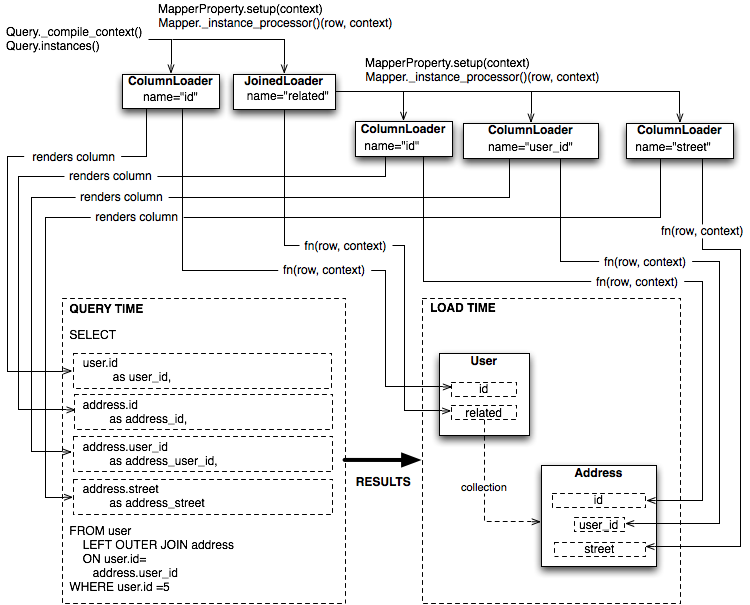
图20.12:连接急切加载中loader strategy的遍历
SQLAlchemy早期填充结果的方法使用了一个传统的遍历,将固定的对象方法和每个接受行的策略联系起来并对应工作。在0.5版本中第一次引入的可调用加载系统,极大地提升了性能。因为很多和行处理有关的决定只要在最开始做一次,而不是对每行都做一个决定,很多没有作用的函数调用就被消除了。
会话/标识映射
在SQLAlchemy中,Session对象为ORM的实际使用(即加载和持久化数据)呈现了公共的接口。它提供了对指定的数据库连接进行查询和持久化操作的入口点。
Session除了作为数据库连接的入口,还维护了一个集合的引用,这个集合包含内存中所有与此Session相关的映射实体。通过这种方式,Session实现了标识映射(identity map)和工作单元(unit of work)模式——两个由Fowler定义的模式。标识映射为一个特定的Session维护了一个所有对象的映射,映射的ID在数据库中是唯一的,消除了重复的标识带来的问题。工作单元建立在标识映射上,提供了一个自动化系统,用最高效的方式将所有状态的变动持久化到数据库中。实际的持久化步骤叫做“刷新”(flush),在现在的SQLAlchemy中,这个步骤通常是自动的。
开发历史
Session一开始是一个多半隐藏着的系统,负责发送刷新的单一任务。刷新过程包括发送SQL语句到数据库,与工作单元系统跟踪的对象的状态相一致,同步数据库和内存中的状态。刷新一直是SQLAlchemy所做的最复杂的操作之一。
在早期的版本中,对刷新(flush)的调用是在一个叫commit的方法之后,这个方法是在一个隐式的、局部于线程的objectstore对象上的。在SQLAlchemy 0.1中,不需要调用Session.add,也根本没有显式的Session概念。用户所做的步骤就是创建映射,创建新对象,修改由查询加载的已存在的对象,然后将所有的变化通过objectstore.commit命令持久化。操作集合的对象池无条件是模块全局的和线程局部的。
objectstore.commit模型直接吸引了最早的一批用户,但这个模型因为不灵活很快就遇到了困难。新接触现在的SQLAlchemy的用户可能会痛恨一大堆的步骤:为Session对象定义工厂(可能是注册),将对象一次组织到一个Session里。但这比早期整个完全是隐式的系统更可取。0.1版本便利的使用模式在现在的SQLAlchemy中仍然广泛存在,会话注册一般是配置为使用线程局部作用域。
Session本身只在SQLAlchemy 0.2中引入,轻率地模仿了Hibernate中的Session对象。这个版本的特性有集成事务控制,Session可以通过begin方法放置到一个事务中,并通过commit方法完成。objectstore.commit方法重命名为objectstore.flush,新的Session对象可以在任意时刻创建。Session自身从UnitOfWork对象中分离出来,后者仍然是一个私有的对象,负责执行实际的刷新操作。
当刷新过程成为用户显式调用的方法时,SQLAlchemy 0.4系列引入了自动刷新(autoflush)的概念,意思是每次查询之后立即发送刷新。自动刷新的好处是,查询发送的SQL语句可以访问内存的准确状态,因为所有的改变都已经发送过。早期的SQLAlchemy不包含这个特性,因为最常见的使用模式是,刷新语句同时会永久地提交改变。但引入自动刷新后,伴随而来的还有一个叫事务型(transactional)Session的特性,提供了在事务中可以自动启动一个Session,并会一直存在到用户显式调用commit为止。有了这个特性,flush方法再也不需要提交它刷新的数据,于是可以安全地自动调用。Session现在提供了通过刷新一步步在内存状态和SQL查询状态之间进行同步的功能,在显式调用commit之前,不会进行永久的改变。这种行为实际上和Java的Hibernate一模一样。然而,SQLAlchemy是基于Python的Storm ORM的相同行为,在0.3版本中引入这种使用风格的。
版本0.5引入了事务后消除(post-transaction expiration),带来了更多的事务集成。默认情况下,每次commit或rollback后,所有Session中的状态都会被消除,在后续的SQL语句重新SELECT数据时再重新生成,或是新事务的上下文中访问未被消除的对象的属性时重新生成。起初,SQLAlchemy建立在SELECT语句无条件地尽量少的发送的假设上。因为这个原因,在提交时消除的行为在后来变慢。然而,它完全解决了包含过期数据Session的问题,使它可以在事务后用一种简单的方式加载新的数据,而不需要重新构建所有已经加载的对象。早先,这个问题似乎没有合理地解决Session何时该将当前状态认定为过期并不明显,因此在下一次访问时产生了昂贵的SELECT语句集合。然而,一旦Session移动到一个“总是在事务中”的模型,事务端的重点就自然成为了数据消除,因为高度隔离的事务的本质就是它直到提交或回滚都看不到新的数据。当然,不同的数据库和配置,事务隔离的方面不同,也可能根本就没有事务。SQLAlchemy的消除模型完全可以接受这些使用模式,开发人员只需要清楚,低隔离层次可能在多个回话共享同一行时,在一个会话中暴露未隔离的改变。这和直接使用两个数据库连接时发生的情况根本没什么不同。
会话概览
图20.13展示了一个Session和它处理的主要结构。
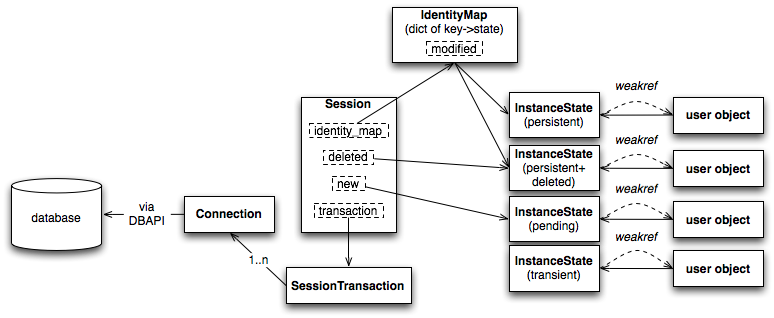
图20.13:会话概览
面向外部的部分是Session和用户定义的对象的集合,每个用户定义的对象都是一个映射类的实例。这里我们看到,映射的对象保存了一个到InstanceState的引用,这个对象记录了ORM的状态,包括即将发生的属性改变和属性消除状态。前面“映射剖析”章节讨论的属性instrumentation,InstanceState是在其中的实例级部分——与在类级的ClassManager相对应(前面讲过,映射类及其实例之间是对称的,行为有某种对应关系——译者注)。它代表和类关联的AttributeImpl对象,维护映射对象的字典的状态(即Python的__dict__属性)。
状态跟踪
IdentityMap是一个从数据库ID到InstanceState对象的映射,是为叫做*persistent*的有数据库ID的对象工作的。IdentityMap的默认实现和InstanceState一起工作来管理自己的大小,方式是在指向一个实例的所有强引用都删除后,把这个实例也删除——这和Python的WeakValueDictionary的工作方式是一样的。Session对所有标记为*dirty*或*deleted*的对象,以及标记为*new*的pending对象,通过创建到这些对象的强引用来保护这些对象免于垃圾回收。所有的强引用都会在刷新后被丢弃。
InstanceState还在维护特定对象的属性“变了啥”中扮演着重要的角色。它使用一个“改变时移动”的系统,将特定属性“从前的”值,在将到来的值赋值到对象当前的字典之前,在存储到一个叫committed_state的字典中。在刷新时,committed_state和对象关联的__dict__的内容会进行比较,产生每个对象的净改变。
对于集合的情况,一个单独的collections包和InstrumentedAttribute/InstanceState系统合作,为一个特定映射对象的集合维护一个净改变的集合。常见的Python类如set,list,dict都在使用前进行继承并根据历史跟踪的增变方法进行扩展。集合系统在0.4版本修订为可扩充的,可以在任何类似集合的对象上使用。
事务控制
Session的默认使用状态,为所有的操作维护了一个活动事务(open transaction),当调用commit或rollback时结束。SessionTransaction维护了零到多个Connection对象的集合,每个对象代表一个在特定数据上活动事务。SessionTransaction是一个惰性初始化的对象,一开始没有任何数据库的状态。当一个特定的后端需要参与语句执行时,和那个数据库相关的一个Connection才被加入到SessionTransaction的连接列表里。虽然一段时间只有一个连接很常见,但有时候会因为Table,Mapper相关的配置,或因为操作中的SQL结构,需要为特定的操作使用特定的连接,这样多个连接的场景也能支持。多个连接时如果DBAPI提供了相应功能,也能使用事务的两阶段行为进行协作。
工作单元
Session提供的flush方法把它的工作移交给一个叫做unitofwork(工作单元)的独立模块。前面已经提到,刷新的过程大概是SQLAlchemy中最复杂的功能。
工作单元的工作是将一个Session中的所有*pending*状态移出到数据库中,并清空Session的new,dirty和deleted集合。一旦工作完成,Session在内存中的状态。主要的挑战在于正确决定持久化的步骤,然后按正确的顺序执行。这包括决定INSERT,UPDATE,DELETE语句的列表,包括相关行删除或移动后带来的连锁反应(cascade)。保证UPDATE语句只包含实际修改过的列。在新生成的主键ID可用时,建立“同步”操作将主键列的状态复制到引用的外键列。保证INSERT语句按对象加入Session中的顺序产生,并尽可能的高效。保证UPDATE和DELETE语句按确定性的顺序产生,减少死锁的可能。
历史
工作单元的实现是从一个即兴写出的结构组成的混乱的系统开始的,它的开发可以类比为在没有地图的情况下找到走出森林的路。早期的缺陷和缺少的行为用后扩充的修复解决了。虽然0.5版本进行了一些重要的重构,但直到0.6版本,工作单元变得稳定,可理解,并用大量测试覆盖时,才可以进行彻底的重写。用数周时间考虑一个可以用一致的数据结构驱动的新方法后,用这个新模型进行重写只花了几天的时间,因为这时候思路很容易理解。新实现的行为可以用已有的版本进行细致的交叉验证,也对新的实现很有帮助。这个过程展示出,第一次的迭代不管多么糟糕,只要它提供了一个可工作的模型,就还是有价值的。它还展示出,对子系统的彻底重写经常不止是合适,更是困难系统开发的一个完整的部分。
拓扑排序
工作单元背后的关键范式是将一系列的行为组装,用一个数据结构进行表示,结点代表单个步骤。在设计模式的说法中这叫做命令模式(command pattern)。在这个结构中,一系列的“命令”使用拓扑排序(topological sort)组织为特定的顺序。拓扑排序是根据偏序(partial ordering)将元素排序的过程,在排序中,只有特定的元素必须在其他元素的前面。图20.14展示了拓扑排序的行为。
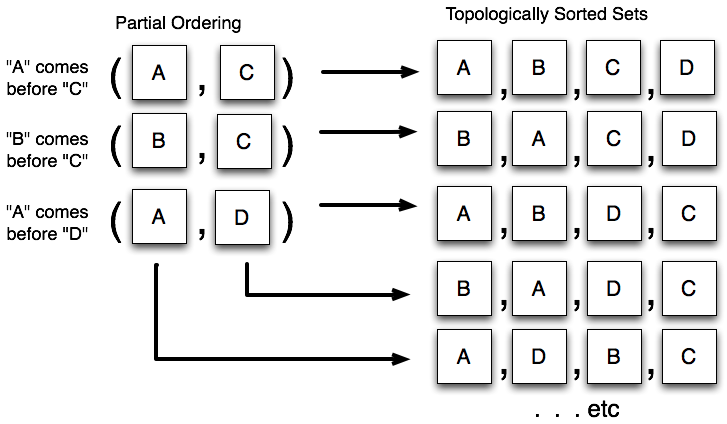
图20.14:拓扑排序
工作单元基于持久化命令间必须的先后关系构造偏序。这些命令然后经过拓扑排序后按顺序调用。哪个命令在哪个命令之前主要是基于联系起两个Mapper对象的relationship推断出——总体上,因为relationship暗示着一个Mapper有对另一个的外键依赖,所以认为一个Mapper依赖于另一个。相似的规则在多对多关联的表中也存在,但这里我们重点关注一对多和多对一的关系。外键依赖。。。但同样重要的是,这个顺序允许在很多平台上只会在INSERT实际发生时生成的主键ID,从一个刚刚执行的INSERT语句的结果中,填到一个将要INSERT的有依赖的行的参数列表中。对于DELETE,使用相反的顺序——有依赖的行先于它们所依赖的行被删除,因为它们外键引用的东西不存在时,它们也不会存在。
在系统中拓扑排序出现的两个层次,工作单元起到重要作用。第一个层次基于Mapper间的依赖将持久化步骤组织进桶,也就是很多装着和特定类相对应的对象的桶。第二个层次将零到多个这样的桶分成更小的批,来处理引用循环或自引用的表。图20.15展示了在插入一些User对象后接着插入Address对象时生成的“桶”,其中一个中间的步骤将新生成的User主键值拷贝到每个Address对象的user_id外键列。
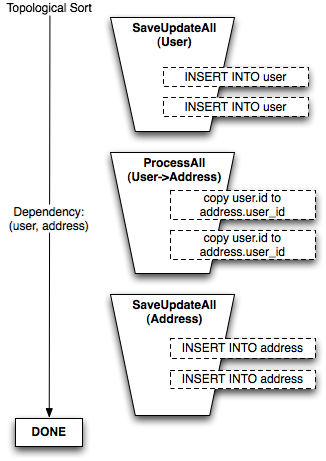
图20.15:按mapper组织对象
在每个mapper排序的情况下,任意数量的User和Address对象都可以刷新,而不会影响步骤的复杂性,或导致需要考虑多少“依赖”。
排序的第二个层次是在单个mapper的范围内基于对象间的直接依赖组织持久化步骤。这种情况何时会发生的最简单的例子是,有一个包含了到自身的外键依赖的表。表中的特定行需要在同一个表中引用它的另一个行之前插入。另一个例子是一组有循环引用(reference cycle)的表:表A引用表B,表B引用表C,表C又引用表A。一些A的对象必须要在其他对象之前插入,才能允许B和C的对象也插入进来。一个引用自身的表是循环引用的一个特例。
为了决定哪些操作可以remain in their aggregated,对每个Mapper桶上,和Mapper桶分解成的对象的命令的庞大集合,在mapper间存在的依赖集上应用环路检测算法,使用了一个在Guido Van Rossum的博客上找到的环路检测算法的修改版本。涉及到环路的桶就被分解成对象的操作,通过将新的依赖规则从每个对象的桶加入每个mapper的桶,将对象的操作混入mapper的操作的集合。图20.16展示了User对象的桶分别为单个对象的命令,导致加入了一个从User到自身的叫做contact的relationship。

图20.16:将循环引用组织为独立的步骤
桶结构的原理是,它允许尽可能多的对共同的语句进行批处理,既减少了Python中需要的步骤数,又可以和DBAPI进行更多的有效交互。有时候用一个Python方法调用就可以执行上千条语句。只有当mappper间的循环引用存在时,才会使用更昂贵的单个对象依赖的模式,但也只是在对象图中需要的部分才使用。
结论
SQLAlchemy从诞生之初就有很高的目标,想成为功能最丰富、最通用的数据库工具。它做到了这一点,并且一直将关注点放在关系型数据库上,认识到用深度、透彻的方式支持关系数据库的实用性是一项大的事业。甚至在现在,我们还不断发现这个事业的范围比以前想象的要大。
为了从每个领域的功能中提取最有价值的东西,SQLAlchemy打算使用基于组件的方法,提供了很多不同的模块单元,应用程序可以单独使用或是组合起来使用。这个系统的创建、维护和交付都一直是很有挑战的。
SQLAlchemy打算缓慢发展,这是基于一个理论——系统地、有基础地构建稳定的功能最终会比没有基础地快速发布新功能更有价值。SQLAlchemy用了很长的时间构建出一个一致的、文档齐全的用户故事。但在这个过程中,底层的架构一直领先着一步,导致在一些情况下会出现“时间机器”效应,新功能可以几乎在用户需要它们之前添加进来。
Python语言是一个很好的宿主语言(如果有些挑剔的话,特别是在性能方面),语言的一致性和极大开放的运行时模型让SQLAlchemy可以比用其他语言写的类似产品有更好的用户体验。
SQLAlchemy项目希望Python在尽可能广的领域得到广泛深入接受,并且关系数据库的使用也一直生机勃勃。SQLAlchemy的目标是要展示关系数据库,Python,以及经过充分考虑的对象模型都是非常有价值的开发工具。